Institute Quantum Phenomena in Novel Materials
Data Science
Our interest is to develop machine learning as a tool to understand magnetic materials and the concepts of fundamental physics arising from them. The long-term goal is the systematic analysis and search for interesting and useful properties in exotic states such as the quantum spin liquid, arising in quantum and frustrated magnets by using machine-learning and big data methods. Using available databases, materials with magnetic ions and known crystal structures that are relatively unexplored will be selected for further investigation. These materials must them be further filtered based on whether their Hamiltonian is likely to support exotic physics. The Hamiltonian can be determined using experimental measurements of the magnetic spectrum by the traditional method of fitting to a model. As a first step towards a more efficient and accurate way to determine the magnetic Hamiltonian, the software package SpinW which can be used to calculate the spectrum for given Hamiltonian and spin configuration will be used to ‘train’ the machine alongside other software packages. In order to compare the calculation with real (inelastic neutron scattering) measurements, two further aspects must be taken into account. The simulated system should be at an energy minimum (ground state) and the measurement data has many impairments (background, artefacts or different scale factors). Here an auto encoder concept is planned to be used.
The reason for using machine learning to determine Hamiltonians from data rather than traditional methods is that, in many cases, it is not possible to fit the theory directly to the measurements because the calculated results are multi-dimensional and/or have a large number of dependent parameters. On the other hand, the underlying magnetic band structure is smooth and systematic allowing interpretation using pattern recognition by machine learning algorithms.
The next step would be to develop machine learning concepts to find phase transitions e.g. as a systematic function of Hamiltonian parameters or by changing temperature and applied magnetic field to a fixed Hamiltonian. Here goal is to predict the magnetic properties of these materials and select the most interesting candidates for experimental investigation thereby focusing resources and time efficiently.
We started to planning concepts for data and scientific workflows. A key point is the automatic analysis and comparison of experiment and simulation data sets. By using material data bases and Monte-Carlo methods to feed the machine learning algorithms with physical simulations (partly also MC methods), we will generate an environment of a large number of datasets for testing new computer science algorithms. There is a clear separation between the data analysis and the data creation (in the useful space), but the benefit is the result of the interplay between computer and condensed matter physics (domain) science. In order to realize the concept of analysis pipelines, it is necessary to develop Python interfaces (e.g. from matlab software) and to achieve a high degree of parallelization (e.g. GPUs) in the applications.
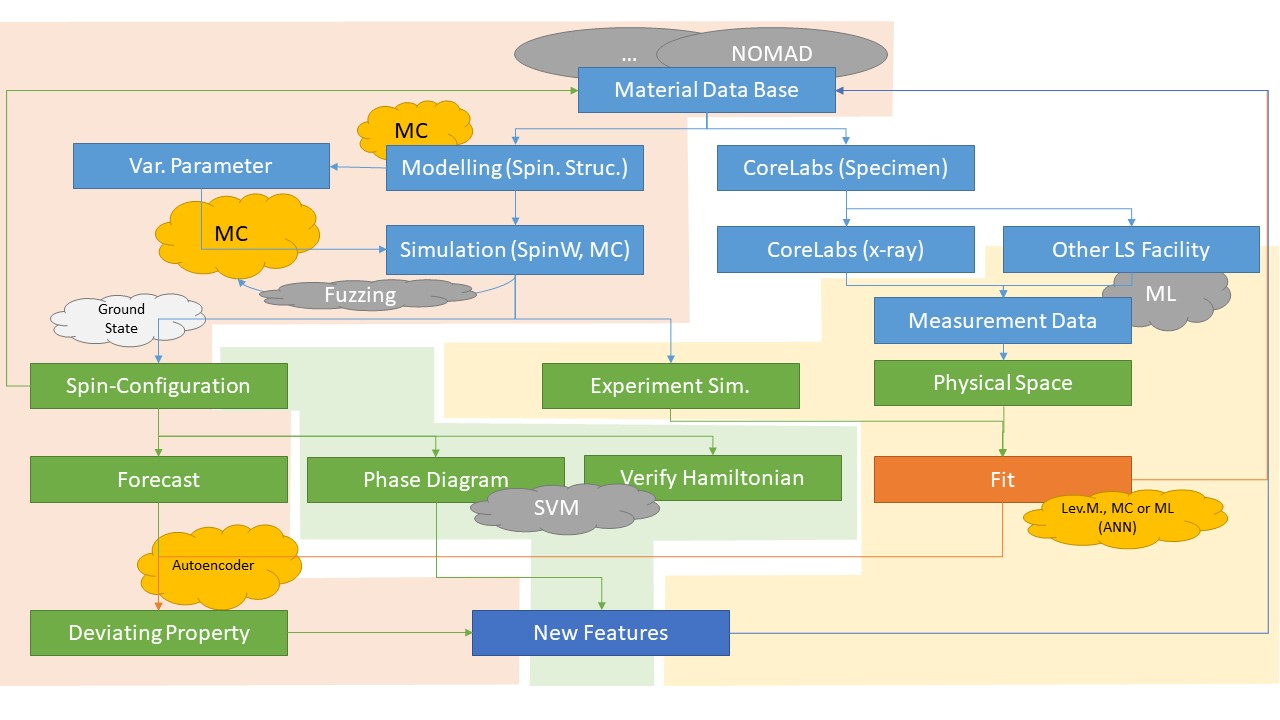
Draft for a scientific workflow concept.
Data Engineering
Data engineering is the aspect of data science that focuses on practical application of data sets and data analysis. This include building and maintaining the organization of data pipeline systems. It make it sure that the data is using is clean, reliable, and prepared for whatever use cases may present themselves. Data engineers wrangle data into a state that can then have queries run against it by data scientists. We will install a database to store all meta information of the whole data analysis process.